Proyecto
SkillMatch AI
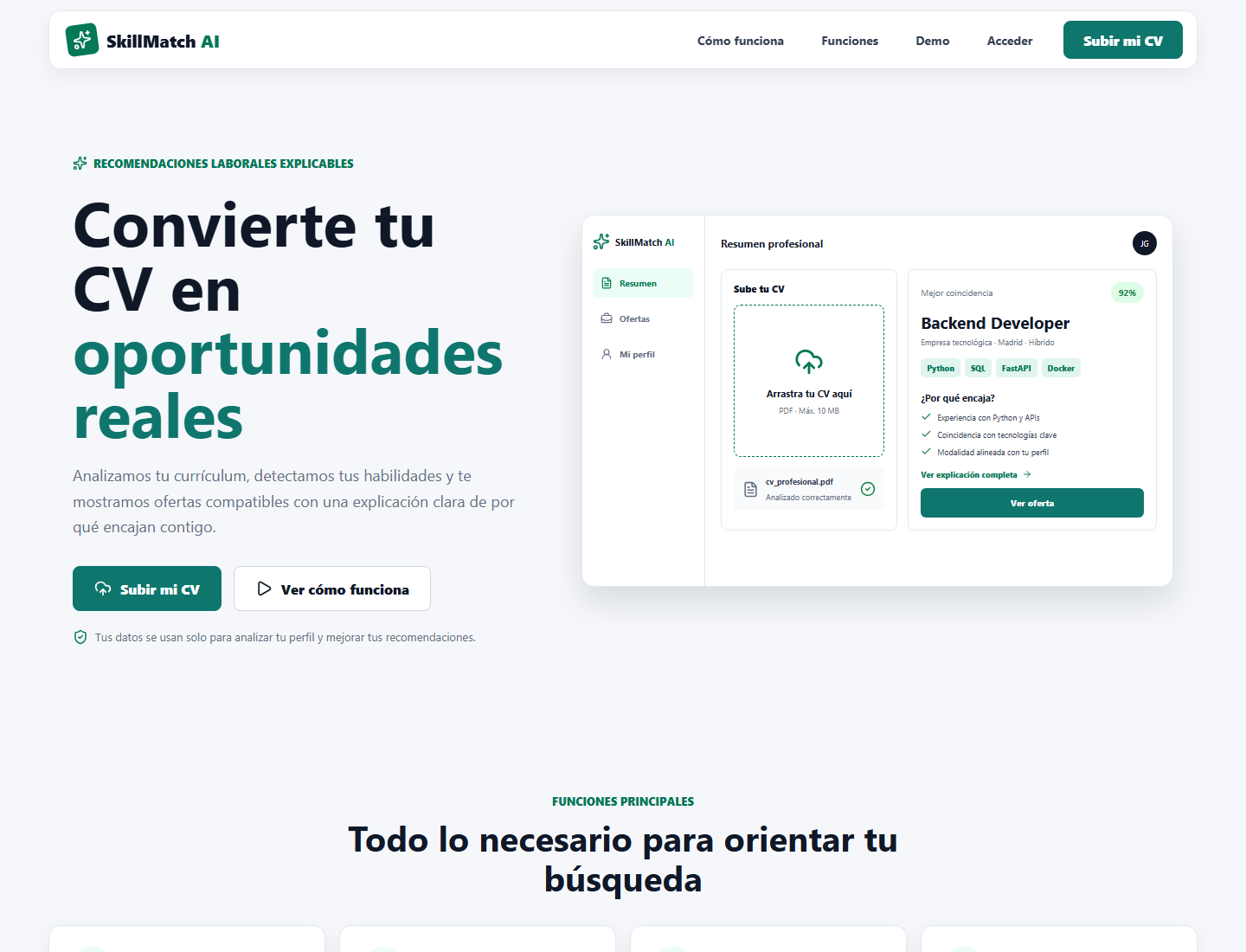
SkillMatch AI es una aplicación web para orientar la búsqueda laboral a partir del análisis de un CV. Extrae información profesional del documento, construye un perfil estructurado, busca ofertas tecnológicas relacionadas y calcula un ranking de compatibilidad combinando reglas de skills y similitud semántica. El resultado no solo ordena las ofertas, también explica qué coincide con el perfil y qué habilidades faltan.
Problema que resuelve
Buscar empleo obliga a comparar manualmente el contenido de un CV con descripciones de ofertas muy heterogéneas. Muchos portales priorizan por palabras clave o criterios poco transparentes, sin explicar por qué una oferta encaja con una persona candidata.
Objetivo
Reducir el tiempo de revisión de ofertas y hacer visible el criterio usado en el ranking, ayudando a la persona candidata a entender qué oportunidades encajan mejor con su perfil sin sustituir su decisión final.
Stack técnico
Funcionalidades principales
- Registro, login, logout y restauración de sesión.
- Verificación de email y recuperación de contraseña.
- Subida y procesamiento defensivo de CV en PDF.
- Construcción de perfil profesional estructurado.
- Detección de skills, experiencia, idiomas, formación y tipo de perfil.
- Búsqueda asíncrona de ofertas por perfil.
- Ranking de recomendaciones paginado y explicado.
- Guardado, descarte y marcado de ofertas como postuladas.
- Análisis de CV en PDF dentro del flujo de la aplicación.
- Configuración Docker separada para desarrollo y producción.
Decisiones técnicas destacadas
- Matching híbrido con 65% reglas de skills y 35% similitud semántica.
- Embeddings de 384 dimensiones almacenados en PostgreSQL con pgvector.
- Validación defensiva de PDF con extensión, MIME, cabecera real, tamaño, páginas y texto mínimo extraíble.
- Sesiones opacas con cookie HttpOnly en lugar de tokens en localStorage.
- Contraseñas con Argon2id y migración automática desde bcrypt.
- Worker separado para emails con payload cifrado mediante Fernet y reintentos escalonados.
- Rate limiting persistente en PostgreSQL para flujos sensibles.
- OpenAPI disponible en desarrollo y deshabilitado en producción.
Qué aprendí o qué demuestra
El proyecto demuestra cómo combinar reglas explícitas y embeddings para crear recomendaciones interpretables. También refuerza la importancia de normalizar skills antes de comparar perfiles, persistir la versión del algoritmo y separar responsabilidades entre autenticación, procesamiento de CV, importación de ofertas, matching y correo.